How I Use AI Tools Everyday: Leveraging Claude and ChatGPT
Table of Contents
- Thoughts on Intentionally Leveraging Popular Generative AI Tools
- tl/dr—Bottom Line Up Front
- Categorizing My LLM Use-Cases
- Predictions for the Future
- Appendix: Distinguishing Features
- Appendix: Frustrating Aspects of Working with Generative AI
- Appendix: Generative AI Product Alternatives
- Appendix: Human Knowledge and the Limits of Training Data
Thoughts on Intentionally Leveraging Popular Generative AI Tools
For the past six months,1 I’ve intentionally incorporated a variety of LLM tools into my day-to-day work. With a base-tier subscription to both Anthropic Claude 3.5 Sonnet and OpenAI ChatGPT-4o, I strived to evaluate their effectiveness for the following objectives:
- Determining if the paid product version is superior to the free version, thus worth paying for.
- Comparing and contrasting the effectiveness of each model in navigating a combination of personal and professional use cases.
- Deciding, based on my experience, which product makes sense to continue working with—I hypothesize that both products are functionally similar and there is a nontrivial overhead in prompting queries in both UIs.2
- Evaluating some of the hype and claims seen online about AI and the workforce.
tl/dr—Bottom Line Up Front

Yes. Paying3 the modest price for a Pro version of either model is worth the expense, primarily to avoid the frustrating “Message Limit” error and to get access to the latest models and additional features offered by both companies. Most every time I leveraged any LLM for assistance, I was able to run faster and jump higher.
Not all use-cases benefit from an LLM4, but for those I detail below, I felt I was more productive, efficient, and able to complete tasks on the edge of my competency zone. After several months simultaneously leveraging both products, I found Claude to be my subconsciously preferred model. ChatGPT tended to be more verbose in response, whereas I felt Claude responded more succinctly. Additionally, when working with code, the side-by-side prompt and editor (artifacts) really made it cognitively easier for my brain to process the response and the generated code as two separate entities.
Pricing and Comparative Value
This assessment is based on a ~$20/month subscription.5 I also think there is diminishing marginal utility being squeezed from each new model release, and, just like the proliferation of content streaming platforms, there are a growing number of options in AI models to subscribe to.
So what is having a generative AI tool worth to me? $200/month stretches credulity (spoiler: I decided to try it, but that’ll be a post for the future), but I did find working with LLMs valuable enough that even pricing up to ~$50 a month seems palatable for the improvements to basic searches,6 programming help,7 brainstorming ideas, and drafting outlines.
What’s Next for Me
Well, I decided to splurge on ChatGPT Pro; my rationalization is that if Sam Altman told me, “For $200 I’ll let you spend one month with our latest tech,” I’d ask, “Cash or check?” He also posted on Twitter that they lose money, so I must be getting a good deal, right?
With access to more advanced features, I’m going to focus on evaluating the reasoning model and the new Operator functionality. For now, I’ll continue to use Anthropic Claude for the occasional programming that I do, but that is not a daily occurrence for me.
The other thing I’d like to do is integrate my model interactions via command line. I have my eye on this library published by Simon at https://llm.datasette.io/en/stable/ and experiment with the direct IDE integrations via VS Code extension Amazon Q.
Categorizing My LLM Use-Cases
This deep dive is not a technical assessment of any models’ performance against benchmarks; it’s, as they say, all about vibes. From a workflow perspective, I prefer typing text prompts and reading responses in a separate window/tab/app than the one I am focused on. I did not try any of the audio or video prompting features, but there were certain prompts with which I included an image or an uploaded code file for analysis.
I’ll be the first to admit that the majority of what I consider interesting examples pertain to my work and therefore are not publishable here, but looking back over my chat history, I roughly categorize them into the following broad buckets8:
- Replacing Traditional Search (Google/DuckDuckGo)9—both models do a competent job replacing static Google searches that summarize well-known queries and sometimes real-time information (YMMV).
- Brainstorming—prompting can be a very effective way to “talk” through an idea, including general knowledge review and providing feedback on my own works.
- Application Development—generating initial drafts of ideas like “design a kotlin enum class for a given data structure,” troubleshooting both compilation and runtime error messages, and copying unfamiliar code into the chat to ask for an explanation.
Paying for an ad-free10 search experience is amazing, and getting context-aware and hyper-localized code is great, but the best value I get from LLMs is help in navigating decades worth of information that would be impossible for me to have learned traditionally. I will note that whenever possible, I try to follow its output back to real content on the web—probably another factor contributing to my increasing use of traditional search.
Integrating LLMs into My Workflow: Augmentation and Automation
Harvard Business School11 published a working paper on navigating the future working with AI as either a handoff approach (Centaur) or wholly new integrated (Cyborg) practice. Centaurs, half-horse, half-man, represent a segmented hard switch, toggling between an AI tool and the task at hand, resulting in an almost bidirectional process within a task set. Cyborgs infuse generative AI through the entire workflow, either eliminating the original workflow or inventing a new process altogether.
For the categories of replacing traditional search and brainstorming concepts, I felt that I had created a new workflow for problem-solving. That, like a cyborg, these processes were wholly new approaches to problem-solving and not a replacement of existing workflows. Prompting became the core mechanism to find information, brainstorm ideas, and ultimately resolve my query within the prompt/response window.
Specific to application development and writing, especially with dedicated tools for both, using LLMs felt analogous to the centaur approach. I much preferred to keep prompts in a separate window, moving the relevant changes back and forth, especially error messages and small changes. I cannot stress how frustrating it was to get either initially un-runnable code, or worse, to get 80-120 lines of code spewed out, totally disrupting my focus. Same goes for writing: While I might brainstorm an outline or flesh out ideas with the LLM, when it came time to write an initial draft, I much preferred writing in my own voice.
The point is that integrating LLMs into your workflow involves a variety of decisions to make the best uses of their outputs:
- Do I have enough knowledge to understand and evaluate what is being generated in response to a prompt? It’s important to recognize that AI is not authoritatively correct; it’s just statistically correct.
- Am I augmenting or am I automating a process, and which is best suited for how LLMs work? Some workflows are better as wholly new AI processes, others when augmented by AI, and still others are best left to a human.
- How can I take what is presented and incorporate it effectively into my own work? This is to say, in the area in which you are an expert, how can you best leverage this new tooling? This will look different than leveraging this tooling in areas that are domain-adjacent or unknown to you.
Anthropic recently published a paper looking further at how users interact with their LLM, finding a combination of “Automative Behaviors” and “Augmentative Behaviors.” The key point here is that to get the most value from LLMs, you must decide if the task is automatable or an augmentation.
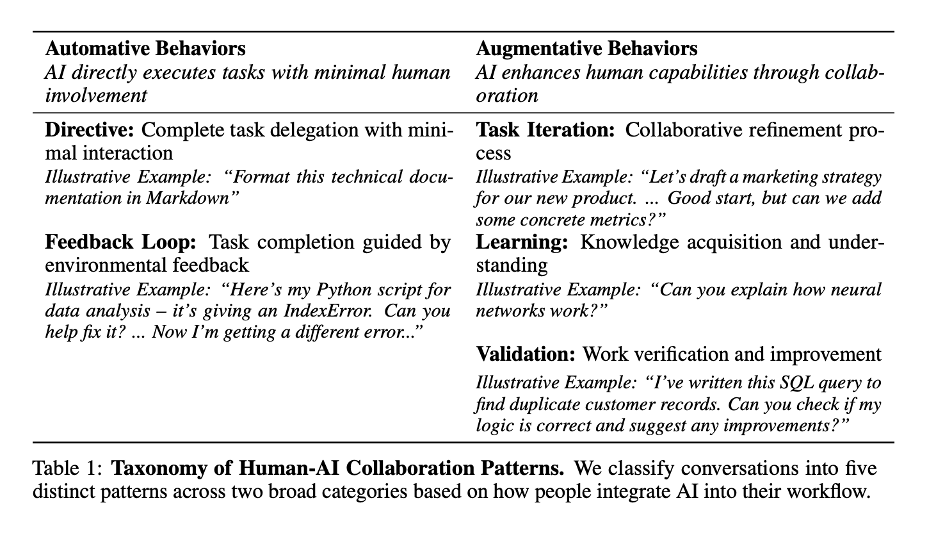
Replacing Traditional Search (Google/DuckDuckGo)
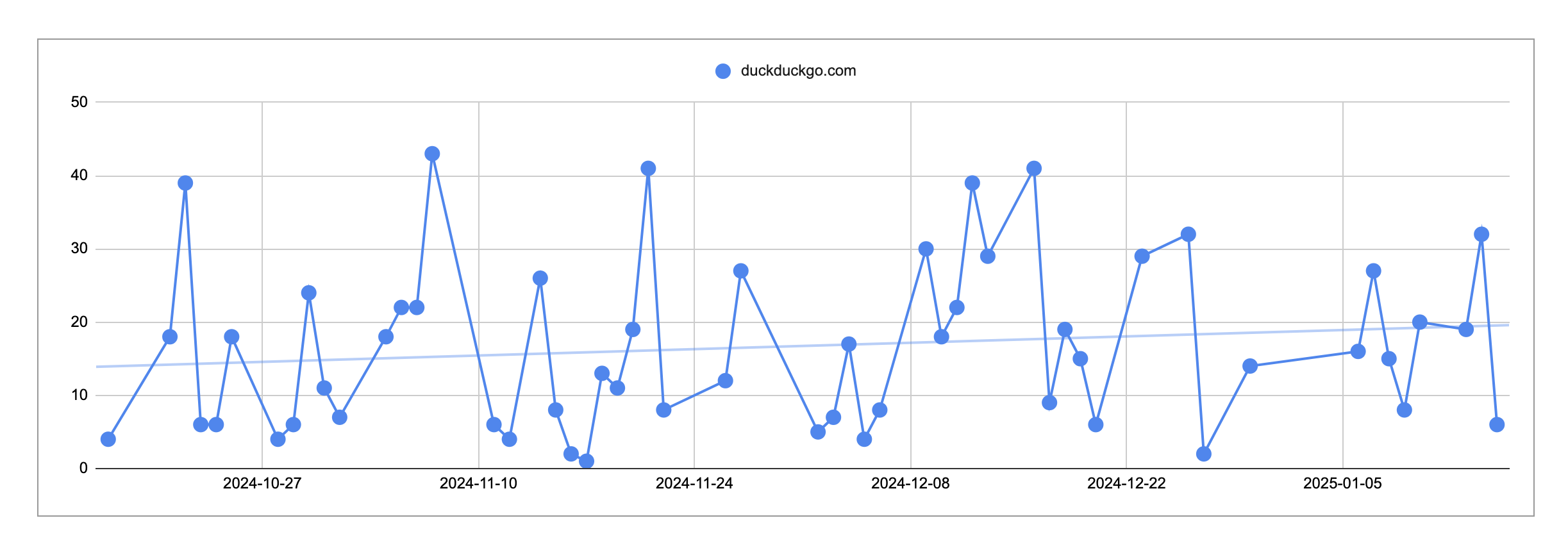
Initially, I had thought I was using traditional search less with AI, but the chart in the section “Both: Citations” reveals I’ve been using traditional search slightly more. However, I am sure that I no longer default to traditional searches, and I will start with Claude for basic queries and generic searches, which are dominated in search results by ad-ridden SEO sites. This is not a replacement for well-written content on Wikipedia.
Having lived through the evolution of direct link-based discovery to index search-based navigation and on to “smart answers,” generative AI does feel like a natural next step. But there are a few glaring problems. First, there is no revenue-sharing or compensation to the creators of original works who can afford to publish for free (irony, I know). Second, enshittification—generative AI tooling has been built with a consumer in mind. How long before ads and revenue demands spoil the party? Third, again, I just cannot trust the outputs of the model, especially when it comes to numbers. Whenever I see a number or math, I double-check the outputs.
Here is a sampling of what I would consider traditional search queries:

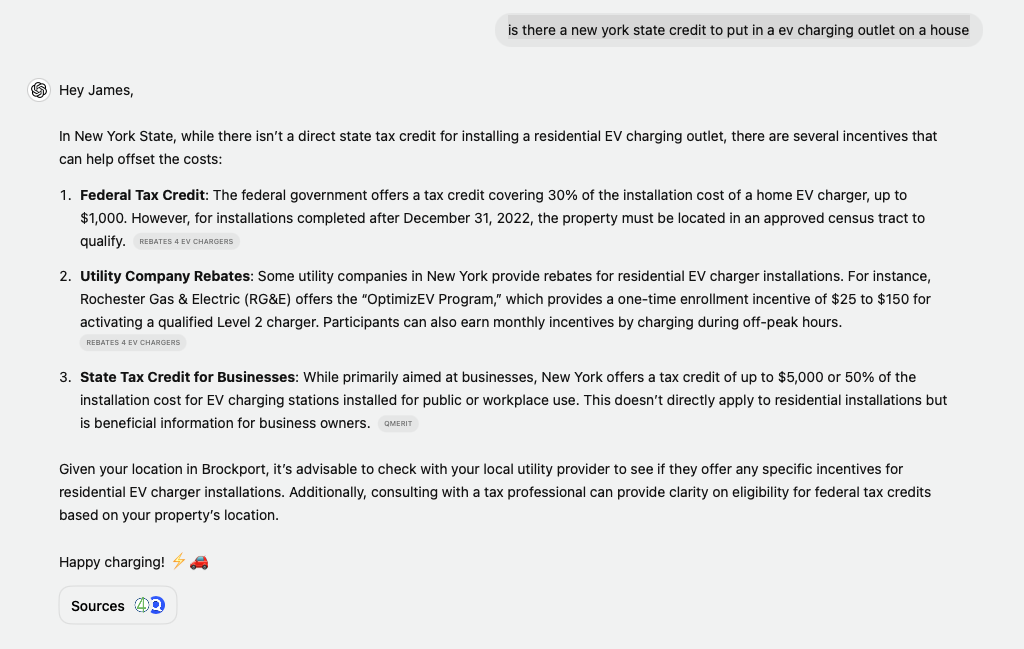
I think the most rewarding aspect of this type of usage is that it quickly leads into brainstorming. For example, my question about NY state rebates for EV chargers quickly turned into “How much does it cost to install one” and then “Does it improve the resale value of the home”—all within one thread and generally reflective of the thought process. Would I be opposed to ChatGPT/Anthropic giving me a siderail of regional licensed electricians? Probably not.
As a bonus to replacing general searches, I’ve found that LLMs are REALLY good at finding information that has very common search terms or that I can’t remember correctly. For example, I couldn’t remember the name of the comedian who had a segment on The Daily Show. But I remembered he was also the “PC” in the famous “I’m a Mac” commercials with Apple. Voila. LLM to the rescue.

Using Generative AI to Brainstorm
With LLMs, I feel as if I have a third voice on my shoulder to bounce ideas off of. Angel, Devil … Robot? Leveraging LLMs is a unique way of both getting feedback on your own thoughts and for exploring others’ perspectives. For example, when writing my book review posts on this site, I can give the content of the post to Claude/ChatGPT and ask it what I might have missed from the material.
On my review of Originals, I wanted to make sure I covered the content of the book, so I asked ChatGPT both to ask me questions about the book and then review what I had written for completeness12.


Here’s another example: At work, I wanted to refresh our engineering meeting and ensure I was soliciting presentations for wide variety of relevant topics. It’s easy to have a quick brainstorming session with generative AI to consider agenda items.
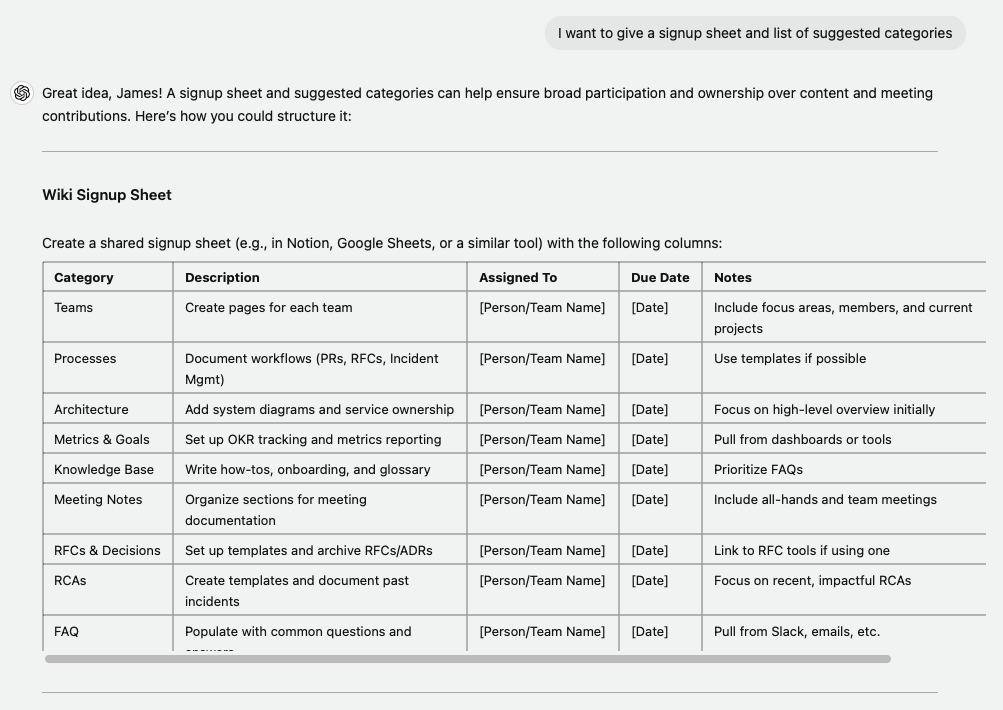
Finally, a classic home budgeting question: “What’s that category?” In the past, I might have Googled “budget template” and gotten back a spreadsheet with 20-30 categories on it. With generative AI, I can give it a list of things I’ve purchased in the last year and have it generate categories relevant to me and my goals. Using the conversational style of AI chats, I felt I came to a tailored budget process rather than defaulting to online templates.
Again, building on the chat history, I can come back to this thread with as many purchases as I make and really find a personal finance system that works for me.

Application Development: Using AI to Code
I started this post with the hypothesis that there will continue to be a demand for the skills needed to build software applications. I still attest that while I have documented many ways generative AI has improved my work, ultimately experts are still needed to review and implement what it generates. Specifically with application development, there are many macroeconomic forces impacting the industry that are unrelated to generative AI, despite what armchair LinkedIn Top Voices might post otherwise.
If you’ve ever interviewed for a technical position, you know that technical assessments are often run inside a web-based code editor, and what do we say when we get any error? “Oh, IntelliJ13 would help me right here with autocomplete …” In the technology industry, we’ve learned to adopt and incorporate better and better tooling to stay focused on writing code that solves business problems. LLM code generation is a progressive step toward generating initial drafts, navigating reams of documentation, and providing context-aware, syntactically correct control statements, but nothing here exceeds the speed at which a domain expert can make changes directly.
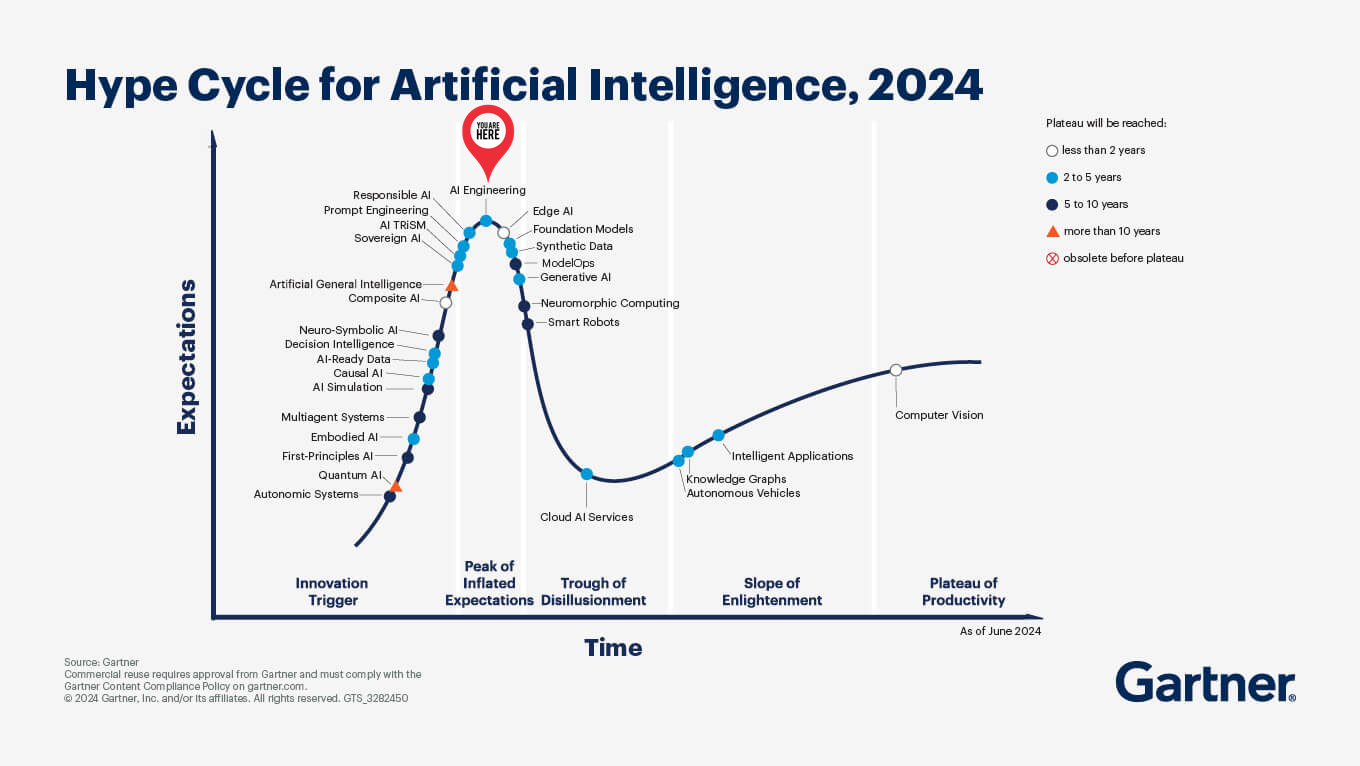
As it pertains to “good enough” solutions, I do think that the code generated with LLMs is worth evaluating and pursuing, but the suggestion that AI will replace engineers I think needs to be viewed in the broader context of business leaders justifying their AI investments, the massive hiring done during the pandemic, the continued positive projections from the Department of Labor, the end of the zero interest rate era and the Gartner AI Hype Cycle. Which, spoiler, has “AI Engineering” at the peak of inflated expectations.
According to Larry Wall, engineers are lazy, impatient, and exhibit qualities of hubris. While that hubris may presently slow adoption of LLM-generated code, software engineers already copy code—be it from StackOverflow, File > New from Template, or just duplicating a file “close enough” and modifying it. It would be foolish not to look to LLMs to create draft code as a starting point.
LLMs can only repeat what exists in their training data, and, as I’ve covered elsewhere, there are date cutoffs within models, which Anthropic has recently been more explicit about highlighting in its responses. Therefore, there will always be a need for software engineers to build something new before it can be present in training data and therefore available to LLMs to replicate.
Generating Initial Drafts of Code with LLMs Is Fast
When measuring the productivity improvements of initial drafts of code, it’s no wonder there is excitement to see reported gains of up to 80 percent. Let’s start with this published headline: GitHub Copilot makes engineers 55 percent faster. Dig into this reported number and you’ll find that the task they were asked to perform was “write a web server in JavaScript.”
I think most engineers would tell you that the task of creating a web server to manage API calls is over and done in the first iteration of the project and rarely revisited; i.e., it is not appropriate to use generative AI’s ability to fill an empty file with hundreds of lines as a long-term productivity improvement.
However, I can attest that generative AI can generate rough drafts fast. The following scripts/html pages were quickly generated and then moved to an IDE for completion. A 55 percent improvement in speed “feels” about right compared to the time to “Create New from Template” or copy/paste from a related source file.
- https://github.com/jsr6720/goodreads-csv-to-md/blob/main/goodreads-csv-to-markdown.py
- https://github.com/jsr6720/jsrowe-status-static-website/blob/main/jsrowe-status.html
- https://github.com/jsr6720/wordpress-html-scraper-to-md/blob/main/wordpressHTMLtoJekyllPosts.py
25 Percent of Google’s Code Is Generated by AI
Let’s look at another claim, this time by Alphabet’s Google. Published in a Q3 2024 earnings report, Google stated, “today, more than a quarter of all new code at Google is generated by AI, then reviewed and accepted by engineers.”
Not much context was given, but if you start to add in all the code updates that tools like renovate and auto-completion perform, it starts to add up. The caveat “reviewed and accepted by engineers” leaves a lot to the imagination. Are these changes reviewed at the time of generation? Or staged as pull requests? I don’t think there’s enough information here to evaluate how much more productive that 25 percent of generated code made the engineering teams. Looking forward to finding out more.
Code Migrations 50 Percent Faster
This time, a real study from Google: “How Is Google Using AI for Internal Code Migrations?” This study provides a use-case of how LLMs can accelerate changes made to a very large codebase (500M+ lines of code). These types of projects seem custom-made for LLMs: There is a boring repetitive task that needs to be done hundreds of times and it has the self-checking mechanism of compiler, unit tests, integration tests, and, most importantly, a human reviewer. The paper claims that an informal comparison suggested a 50 percent reduction in effort to complete this modernization project, and, most importantly, that fewer engineers were needed to orchestrate the changes.
To emphasize this point, when Google posted about this on their blog, they outlined the workflow. Step 1 is “An expert engineer identifies …,” and the final step involves the code being sent to “multiple reviewers.”
DARPA has previously stated their intention to use LLMs to perform C language to Rust language migrations, but I have not seen any updates after this linked article. Having worked on migration projects before, I do think that LLMs will reduce the engineering hours needed to perform the work, tilting the scales toward “migrate” on the migrate/build-new/buy discussions.
I think the future will include more AI-generated pull requests that will help keep systems modern and address the accumulation of technical debt. If AI-generated pull requests help nudge engineering teams to at least evaluate and consider updates, it’s another long-term investment that wouldn’t have been made otherwise.
Code Smell
I should point out that in spite of the above optimistic outlooks for a new source to copy code from, I have encountered many instances of code smell. You cannot offload comprehension; copy/pasting huge sections of code into your project didn’t work when it was copied from StackOverflow or when you duplicated that class a few tree structures over, and it’s not going to work with generated code either. Not to mention that sometimes the best resolution is no code written at all, but I digress.
Note: At times, both models “wrote” code that didn’t work when copied to an IDE. I guesstimate that AI tooling would generate functioning code about 80-90 percent of the time. Based on my experience, it was not a given that any code generated would work on the first try.
Probably the most egregious code smell I experienced while using AI was its propensity to generate all functionality in one file or apply dozens of line changes at once. Never mind importing a common library or knowing what’s available in the project’s utilities folder—AI is very happy to rewrite entire functionalities to ensure the code generated “works.” At this point, you’ve likely reached the 80 percent generation threshold and are better off switching directly to the IDE; apply your expertise to complete the task.
AI is especially susceptible to generic error messages. For example, when prompted to solve a timeout error or file not found, AI is just as happy to extend timeouts to 5 minutes or add the missing file, whereas a human expert would understand that these are often symptoms of an underlying problem. This is remediable by providing more guidance via prompting, but again demonstrates the long-term need for experts who understand how software works.
One particularly humorous experience is AI suggesting one fix that led to me another error message, then, with that fix, led me back to the original error. I would say this is the closest I’ve come to simulating a recursive “autonomous agent”-like experience.14
Another area that AI struggles with is generating version-specific code with features only present in that version. I experienced this most predominately with Apple native development (Objective C->Swift), Ruby (2->3), AWS functionality, and the aforementioned Kotlin major upgrade. These are very real challenges that don’t have a singular right answer from AI tooling but require a software engineer to understand how to resolve.
Security is another glaring example where I can see some unintended side effects. I prompted Claude to troubleshoot a permissions issue with a GitHub action and an s3 bucket. Claude suggested that I modify the s3 bucket permission, but I understood I just needed to grant the assigned role that level of access, not extend permissions in the bucket.15
Predictions for the Future
“Most people overestimate what they can do in one year and underestimate what they can do in ten years.” –Bill Gates
The value generation from software development was never in the written code. It has always been in the translation of business requirements to properly deployed solutions for the customer. For all the focus and hyper-fixation on leveraging AI to complete engineering tasks, I see it at best as a productivity tool that will be competed away as more and more companies adopt established best practices. The allure of perfect requirements, perfect software rests on one faulty presumption: rational humans.
- Models are tools, and the tool with the most context awareness will be most useful. I predict that the current proliferation of chat-based generative AI tools will become a mature landscape of AI tools tailored for specific use-cases.. The LLM that is trained best with the most context awareness for the task at hand will be the most helpful in the long term. Models need to get context-aware and context-specific. This means we will continue to see new products enter the market that utilize existing LLM “seeded” for specific workflows. The winners will continue to be NVIDIA, MSFT Azure and AWS Bedrock which provide the picks and shovels in this gold rush.
- To drive down expense, new training methods will be invented to address energy consumption, which needs to come down drastically for profitability. At no point since I’ve started using LLMs have I considered how much energy I was using.
- Legal and regulatory frameworks will continue to evolve, probably via rightsholders asserting their ownership of material used in models, data privacy legislation, and new case law on fair use. Also, you cannot copyright anything wholly AI-generated at this time.
- Human experts will continue to flourish. LLMs are based on the limitations of known knowledge. I am very excited for a future in which net-new knowledge is acquired instead of reinvented and rediscovered. There are exciting projects where LLMs are leveraged to identify potential compounds for pharmaceuticals, but we still need humans to evaluate their real life implementations. In another study, AI was able to determine the gender of a person based on blood vessel structure. Currently, no one knows how it was able to determine this.
If I were to stretch out my hand to predict 2045, I think that the optimistic outcome is how JARVIS is envisioned in the Marvel universe, or Cortana in the Halo universe. To have the processing power of a personal assistant nudged forward by human ingenuity would be great. Not everyone needs to build robots. If the work is done, can we have a world of creators? The utopian outcome would be the Star Trek model in which humanity boldly goes where no one has gone before to extend humanity’s knowledge of its environment.
Worst-case scenario for humanity would be an Elysium-type outcome where wealth, power, and control are concentrated in the hands of elites who use technology to maintain stratified impenetrable social classes. As I write this, I wonder perhaps if this is not so much a prediction as the current state of affairs. Perhaps I’ll extend my prediction to include that in a world where AI is infinitely better at all possible tasks, humanity no longer finds joys in the pursuit of knowledge and creation.
Conclusion
There really isn’t a scenario in my mind in which I would want to lose access to LLM-based tooling. There have been many positive experiences, and over the past two years, my use of them has only gotten better. Looking at the next five years, I think AI will excel at exploring well-documented topics, quickly prototyping projects, and identifying signals in a very noisy world (datasets). Working with AI in just the last two years reminds me of the evolution from paper map-based navigation to data-fed predictive traffic apps.
On-phone destination routing takes advantage of information we don’t have at available to our senses and is often correct down to the minute about our arrival time. Going back to a world of paper maps seems almost barbaric. “And if you get to the bridge, you drove too far.”
LLMs bring into context a world of information that we won’t always have available for recollection and can create solutions in areas adjacent to my core knowledge much better than I could. But experts are still needed to comprehend what is generated and how it fits into the context of what is produced. Here’s hoping I remain a viable expert into the future.
Appendix: Distinguishing Features
Some nice features I’ve enjoyed.
ChatGPT: Memories
ChatGPT’s Memories feature seems to produce better in-context responses, but I’ve found the memory functionality to be more of a novelty than truly useful. You can find this in Settings > Personalization; allegedly, ChatGPT with memories will provide better responses. In practice, I can’t say that I saw this work spectacularly well.
As you can see, my memory is currently full. Over the course of my evaluation, OpenAI has been steadily increasing its memory capabilities—or at the very least, somehow it seems to “remember” more items the longer I work with it.
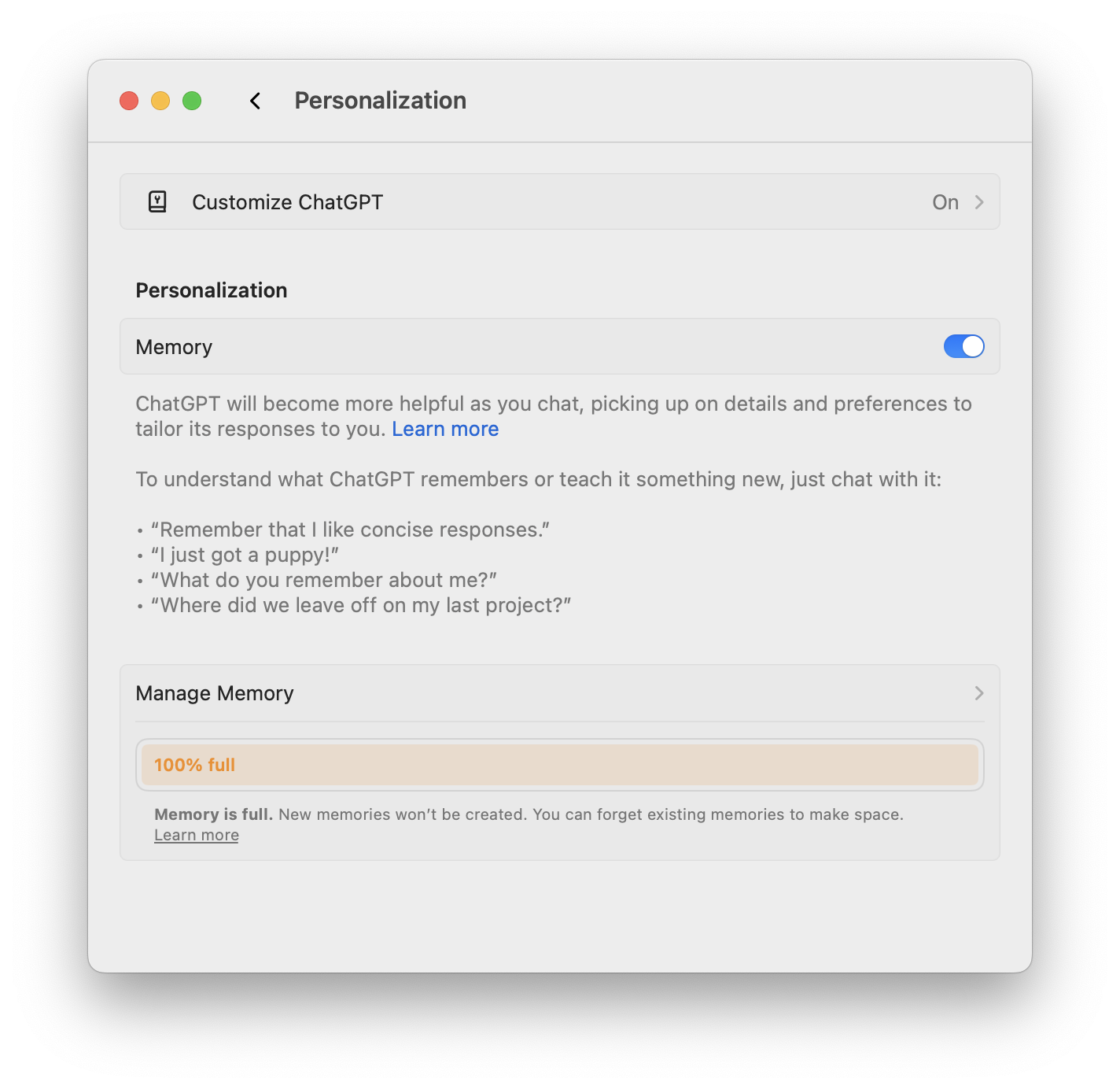
This has been my favorite feature of ChatGPT because it remembers context as I work across prompts and will adjust any given response to reflect that. For example, if I prompt it for some writing help, it will often format the response as a Jekyll blog post because there are many “memories” pertaining to writing blog posts and general troubleshooting of Jekyll. But overall, I haven’t found it better than seeding a prompt with specific instructions, e.g., “Format the following topic as a Jekyll blog post,” as memories tend to pin the response to what you’ve provided before for context.
I concede that Anthropic has “Project Knowledge,” but that doesn’t seem to have the same positive reinforcement across all threads as ChatGPT’s Memories. In fact (and I’ll revisit this in my predictions below), I see contextual world-building as the most compelling feature for the future of these tools.
Both: Project Organization
I liked that I could create a “project” in Claude to build a collection of threads around one defined topic. This came in handy when working on multiple problems with one project. For example, when building an iPad app, I had one thread to work on string localization, another on Swift compilation problems, and another specific troubleshooting thread. I do wish that the Claude AI could share context between all threads and therefore build more context across the project, but I anticipate that the so-called multistep reasoning models will tackle that in the future.
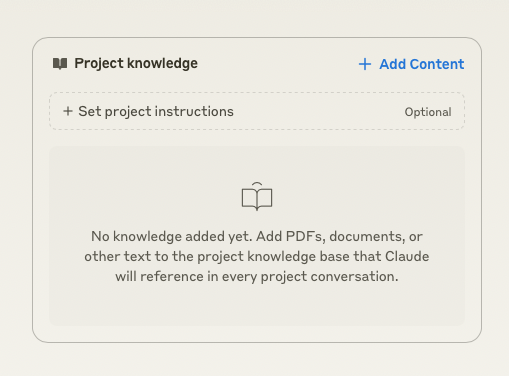
The project concept seems to only exist in the above UI construct. When asked in one thread about other threads, Claude responded it can only “see” the current thread.
There is a prompt to link Google Docs with Claude for more context awareness, but I have not yet tried this feature.

Update: In the time I was evaluating this, ChatGPT released their own project folder organization, but I did not use it during this period. Just from playing around with it, it seems to accomplish the same outcome of organizing related prompts under one folder.

Claude: Artifacts-Side by Side Prompt/Code
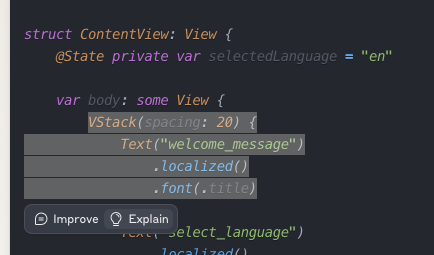
Claude Artifacts were my deciding factor to continue subscribing to Claude Pro. I greatly preferred the split-pane approach with complex prompts. The prompt response would spool on the left side of the screen, and solutions/output on the right. This made processing the response much more coherent than interspersing explanation with solution, and it tracked generated versions right in the UI.
Even though I don’t program complex multi-repo projects anymore, I’ve been able to leverage Claude/ChatGPT to navigate supplemental tasks such as maintaining this website via AWS/Jekyll, build scripts to import older content, and learn more about new technologies I wasn’t well versed in. As seen below, Claude has the ability to highlight code with a quick “Explain This” feature.
Appendix: Frustrating Aspects of Working with Generative AI
Note: I don’t list confabulation i.e. hallucinations, because to work with LLMs is to accept the limitations of a statistics-based, non-deterministic guessing machine. Stacking LLMs to achieve “chain of thought” reasoning I think improves prompt interpretation, but not “smarter” responses.
For all the positive experiences working with generative AI—and it is net positive—I experienced a number of shortfalls.
Both: Citations
Both models do a horrendous job at sourcing original content, aka providing citations. It felt like there was a 50/50 chance whether a link supposedly containing source material would lead to a functioning website. I wish all generative AI LLM disclaimers would read “I generate statistically correct responses based on math.” I understand that LLMs are statistical output engines and no tool currently can connect the generated content with an underlying piece of training data. In fact, since October of last year, my use of traditional search (DuckDuckGo) has actually trended up. I attribute the increased use to validating generative AI results as I’ve experimented with multiple AI tools.
Update: In the time that I was working on this review, Anthropic announced citations for their API that apparently chunks together clusters of underlying data into citable units. This looks very promising and validates my desire to move to API integrations for better control over model settings and latest features.
I’ve noticed just in the past few weeks that both Claude and ChatGPT have been adding disclaimers directly in the response body.
Claude 3.5 Sonnet: “Since my knowledge cutoff is in April 2024, I can’t tell you about current stock levels or exact release patterns for this specific set. However, I can explain how these launches typically work:”
Both: Prompt Limits
Even with the paid plans, I would frequently encounter hard stops with Claude within one day of heavy usage and sometimes also with ChatGPT. This is especially disruptive with Claude because once you’ve reached a message limit on Sonnet, you must start a new thread with Haiku devoid of any of the thread’s previous content. With ChatGPT, you can switch models within one chat thread.


All Generative AI: Compute Cycle Time
I lost count of the number of times I grew frustrated waiting for any model to incorporate small revisions into the larger solution. It was so exasperating that I would often use generative AI to achieve about 80 percent completion,16 then switch to direct editing to complete the task. I don’t foresee any of this tooling replacing experts in their respective fields; however, it definitely allows for exploring knowledge-adjacent areas and rapidly prototyping the zero->one process.
Appendix: Generative AI Product Alternatives
Note: I have left this heading here as it was originally published, but moved this section to a standalone post: A Crowded LLM Field. With a new section outlining my criteria for utilizing these tools.
It was enough work copy/pasting prompts between two chat interfaces that I decided to focus on the models I was already paying for. In writing this comparison, I’ve discovered how many LLMs have proliferated.
I don’t see myself going beyond established companies that offer a paid version of their products, allowing me to opt out of providing training data for other customers. I’ve also shied away from wrapper products from brand-new companies. I have a hard enough time thinking about what data I’m sharing with Anthropic and OpenAI, let alone with some LLM model wrapped product.
Zoom/Slack/Atlassian
It’s worth reminding readers about my disclaimer in the footer that all thoughts on this blog are mine alone. I feel that my current employer is on the forefront of generative AI tool evaluation and adoption, and I’ve been fortunate to witness these tools go from “in the way/borderline useless” to “wow that’s pretty good” over the course of six months.
Particularly, I want to highlight Zoom AI Assistant, which does a decent job summarizing large group meetings and capturing a plurality of action items. I would not rely on it in lieu of a human summary or attending the meeting, but to recap notes it’s a great help. A variety of other vendors offer similar tooling that I’ve been exposed to on various meetings, and all seem to offer basic transcripts and summaries.
The Slack/Jira integration has a great feature that will summarize a thread’s content and generate a title and description for a ticket. It’s good enough for an initial draft and much better than an empty ticket that says “see thread.” Within Jira itself, I find myself using the AI Composer to get a starting draft JQL and then iterate when searching for issues.
Appendix: Human Knowledge and the Limits of Training Data
Note: I have left this heading here as it was originally published, but moved this section to a standalone post: The Unreasonable Ones: Humanity’s Role in an AI World.
In short, an LLM’s capabilities are grounded in its training data, and that training data has limits. That’s why I’m optimistic that even with advances in generative AI capabilities, there will always be a home for human exploration.
On that note, I’d like to thank others for publishing their thoughts on this topic:
- https://crawshaw.io/blog/programming-with-llms
- https://nicholas.carlini.com/writing/2024/how-i-use-ai.html
- https://www.seangoedecke.com/how-i-use-llms/
- https://simonwillison.net/2025/Jan/10/ai-predictions/
Significant Revisions
- Feb 20th, 2025 Moved several appendices to their own posts, focusing the thrust of this post to the AI comparison it started out as.
- Feb 13th, 2025 Originally published on https://www.jsrowe.com with uid 2575976E-E772-40B1-9373-BC918D560C67
- Jan 14th, 2025 Draft created
Footnotes
-
I can trace my following of the industry to two key moments: when “What is ChatGPT” was posted to Slashdot on December 3, 2022, and March 2023 when I first read Reid Hoffman’s book Impromtu. ↩
-
It’s worth nothing that while doing this, I really decided that I wanted to leverage an on-chip local model like Llama or the now rolling-out Apple Intelligence to see if I could achieve a comparable experience without paying anything or leveraging the API experience directly. ↩
-
During my evaluation period, both services cost $21.60 per month for the “pro” version. During this time, OpenAI came out with their $200/month pro plan, demoting the $20/month plan to “ChatGPT-Plus.” ↩
-
I decided to start formally documenting some of the interesting responses in a new repo llm-field-notes on my personal GitHub Account. ↩
-
I predict that in the long term LLM pricing will eventually reflect the costs to produce the technology as currently large cash infusions are needed to keep the company operating. ↩
-
How spam sites in search results are degrading the traditional search experience has been widely covered. ↩
-
StackOverflow can be an unforgiving place for the unitiated. ↩
-
In the spirit of full disclosure, let me say that nothing I share here includes examples from my day job—that wouldn’t be appropriate. However, I will freely share my experiences using AI for my extracurricular and recreational projects. ↩
-
I wish I could scientifically say that my Google (DuckDuckGo) usage has changed by X percent, but I switched machines around the time I started supplementing my workflow with ChatGPT, so I don’t have a good sense of “before.” ↩
-
Yes Disney, I’m calling you out for going from a $7 a month NO ad experience to $15. ↩
-
“Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality.” ↩
-
It was brought to my attention by the wonderful very real humans who provide editing for my work that there is already an opposite of déjà vu, “jamais vu.” Which again, I think, illustrates that experts in their respective fields will always be needed. ↩
-
Yes, I know Real Programmers. ↩
-
This post was primarily focused on leveraging AI chat as a brainstorming and drafting tool. In the future I plan to evaluate “Agents”. ↩
-
With maturity, I recognize that this may be a failing on my part. If I give AI clear instructions, like “Don’t modify roles,” I get different responses to my prompt than when I just say, “Fix this 403 error.” ↩